11. Juli 2018 | Graz
Digitale Epigraphik
Einführung und Grundlagen
Internationale Summerschool “Materialität und Schriftlichkeit” an der Karl-Franzens-Universität Graz
Slides:
https://digicademy.github.io/2018-Graz-Summer_School-Epigraphik
https://bit.ly/2JcnqwG
Max
Grüntgens | Thomas
Kollatz
 @hou2zi0|@kol_t|@digicademy|@inschriften ||
@hou2zi0|@kol_t|@digicademy|@inschriften ||  digicademy || CC-BY 4.0
digicademy || CC-BY 4.0
01
Grundlagen
Digitale und Traditionele Epigraphik
The focus of such a class is not so much an intensive EpiDoc training, but rather demonstrating that structured markup is nothing more than structured thinking about data. The structure of an XML document reflects the structure of an epigraphic edition. Following the strict hierarchy of XML forces one to better organise one’s thoughts, approach towards, and work on an epigraphic document. We have found that it is highly beneficial to be able to process and produce information in a well structured and clearer way, even if the students do not show interest in further DH training.
XML – Extensible Markup Language
Semantik statt Typographie
Generalizing from that sense, we define markup, or (synonymously) encoding, as any means of making explicit an interpretation of a text.
aus: A Gentle Introduction to XML
- Erweiterbar und anpassbar.
- Geräte- wie Plattform-unabhängige Speicherung und Prozessierung von digitalen Texten
- Austausch- und Kommunikations-Format
Extensible Markup Language (XML)
XML trennt Inhalt und Struktur sowie verschiedene Ebenen von Semantik und Metadaten durch Trennzeichen und Schlüsselworte voneinander.
Trennzeichen sind< > & ;
Beispiel
< Schlüsselwort >
& Schlüsselwort ;
Vokabular und Syntax von XML sind anpassbar und erweiterbar. Mit Schema-Sprachen lässt sich ein Regelwerk für projekteigene XML-Dateien erstellen. Ein XML-Dokument bildet eine verschachtelte Baumstruktur.
Elemente (aka “tags”): <element>
<correspDesc>
‖ <correspAction>
‖ | <persName>
‖ | ¦ <forename>Max</forename>
‖ | ¦ <surname>Mustermann</surname>
‖ | </persName>
‖ </correspAction>
‖ <correspAction>
‖ | <persName>
‖ | ¦ <forename>Mina</forename>
‖ | ¦ <surname>Musterfrau</surname>
‖ | </persName>
‖ </correspAction>
</correspDesc>
Sinn: Eindeutige Kennzeichnung und damit Disambiguierung der strukturellen wie semantischen Bestandteile eines Dokumentes:
- Der Bereich ‖ klammert eine einzige Instanz einer Korrespondenz.
- Der Bereich | klammert jeweils die Informationen zum Sender (erste Instanz) sowie zum Empfänger (zweite Instanz).
- Der Bereich ¦ klammert weitere Personendaten.
Attribute
<element
attribut="attributwert">
<correspDesc xml:id="unique_letter_id">
<correspAction type="sent">
<persName xml:lang="de" ref="http://d-nb.info/gnd/118540238">
<forename>Max</forename>
<surname>Mustermann</surname>
</persName>
</correspAction>
<correspAction type="received">
<persName xml:lang="de" ref="http://d-nb.info/gnd/118540987">
<forename>Mina</forename>
<surname>Musterfrau</surname>
</persName>
</correspAction>
</correspDesc>
Sinn: Weitere Spezifizierung bzw. Individualisierung einer semantischen oder strukturellen Information.
Leere Elemente
<element />
<lb/> Lorem ipsum
<lb/> dolor sit
<lb/> adipiscit <handShift/>quid
<lb/> paretur
Sinn: Kennzeichnung von punktuellen Änderungen oder Ansetzung von Ankerpunkten innerhalb eines Dokumentes.
Wohlgeformtheit und Validität
Wenn das XML-Dokument den allgemeinen Syntax-Regeln gehorcht, spricht man von “ Wohlgeformtheit”. Ist das Dokument zusätzlich konform zu einem Schema, spricht man von “Validität”.
Durch die Ansetzung eines Schema-Regelwerks lassen sich XML-Dokumente sehr einfach in konsistenter Form erstellen, da jederzeit ein Feedback zur Regelhaftigkeit des Dokumentes zurückgegeben wird. Viele Text-Editoren greifen zudem auf das zurgundeliegende Schema zurück, um dem Benutzer die im Auszeichnungs-Kontext angebrachten Schlüsselworte per Knopfdruck anzubieten.
Notations- und Syntaxregeln
- Jedes Dokument enhält genau ein Wurzelelement (root element), das alle anderen Elemente des Baumes in sich schließt.
- Regelkonforme Elementnamen sind case sensitive, müssen mit Unterstrichen oder Buchstaben beginnen und dürfen keine Leerstellen enthalten.
-
<Date> ≠ <date> -
<2018_date> ⇒ <date_2018>
-
- Jedes geöffnete Element muss geschlossen werden.
- Es ist keine Überlappung von Elementbereichen erlaubt.
- Elemente ohne Text-Inhalt dürfen auch als selbstschließende bzw. leere
Tags geschrieben werden:
-
<date></date> => <date />
-
- Trennzeichen sind zu maskieren und damit als Entitäten einzufügen, wenn sie als “normale” Zeichen erscheinen sollen:
-
& ⇒ &
-
Maschinelle Verarbeitung
Die Daten konsistent strukturierter XML-Dokumente können mithilfe von Abfrage- und Transformations-Sprachen (XPath, XSLT, XQuery, u.a.) durchsucht, akkumuliert und bspw. in Ausgabeformate überführt werden.
Auf der Grundlage konsistenter Datenhaltung können also Register und Indices akkumuliert werde. Zudem lassen sich Druckvorstufen (pandoc, ConTeXt) für Verlage oder HTML-Ausgaben im Rahmen dynamischer Webseiten (EFES, eXistDB) produzieren.
Standards und die Community
Die Text Encoding Initiative und Epigraphic Documents
TEI: Text Encoding Initiative
The Text Encoding Initiative (TEI) is a consortium which collectively develops and maintains a standard for the representation of texts in digital form. Its chief deliverable is a set of Guidelines which specify encoding methods for machine-readable [=prozessierbare] texts, chiefly in the humanities, social sciences and linguistics.
aus: http://www.tei-c.org
Special Interest Groups

EpiDoc
Epigraphic Documents in TEI XML | text markup for ancient documents
EpiDoc is an international, collaborative effort that provides guidelines and tools for encoding scholarly and educational editions of ancient documents. It uses a subset of the Text Encoding Initiative's standard for the representation of texts in digital form and was developed initially for the publication of digital editions of ancient inscriptions […]. Its domain has expanded to include the publication of papyri and manuscripts […]. It addresses not only the transcription and editorial treatment of texts themselves, but also the history and materiality of the objects on which the texts appear (i.e., manuscripts, monuments, tablets, papyri, and other text-bearing objects).
Arbeitsdefinitionen: Inschrift
Inschriften sind Beschriftungen verschiedener Materialien – in Stein, Holz, Metall, Leder, Stoff, Email, Glas, Mosaik usw. – die von Kräften und mit Methoden hergestellt sind, die nicht dem Schreibschul- und Kanzleibetrieb angehören.
Rudolf M. Kloos, Einführung in die Epigraphik des Mittelalters und der frühen Neuzeit, 2. Aufl., Darmstadt 1992, S. 2.
Arbeitsdefinitionen: Inschrift
An epigraph is any sort of text, from a single grapheme […] to a lengthy document […]. Epigraphy overlaps other competences such as numismatics or palaeography. When compared to books, most inscriptions are short. The media and the forms of the graphemes are diverse: engravings in stone or metal, scratches on rock, impressions in wax, embossing on cast metal, cameo or intaglio on precious stones, painting on ceramic or in fresco [etc.]. Typically the material is durable, but the durability might be an accident of circumstance, such as the baking of a clay tablet in a conflagration.
Wikipedia contributors, “Epigraphy”, Wikipedia, The Free Encyclopedia, https://en.wikipedia.org/w/index.php?title=Epigraphy&oldid=820499672 (23.1.2018).
EpiDoc
Entwicklungsgeschichte – in Kürze

Quelle: http://www.stoa.org/epidoc/
- Subset der TEI
- seit 1999 kollaborativ entwickelt
- im Dezember 2017 Release von Schema und Guidelines Version 9.0
- Mittlerweile wird das TEI-Subset EpiDoc von zahlreichen – zunehmend auch nicht primär epigraphischen – Projekten verwendet
- mehr zur Geschichte https://sourceforge.net/p/epidoc/wiki/About/
Epigraphische Projekte

02
Epigraphic Documents
Ein paar Grundregeln
- TEI ist ein sich entwickelnder Vorschlag. Das "P" hinter TEI steht für proposal, die “5” für die Version. TEI ist kein Zwangskorsett.
- EpiDoc entsteht aus der epigraphischen Praxis der Community für die Community.
- Nur Elemente und Attribute nutzen, die für das Verständnis der Quelle nötig und nützlich sind.
- Sinnvoller Einsatz von TEI setzt ein Konzept voraus (Editionsrichtlinien, Fragestellung, etc.).
- EpiDoc Schema und Struktur ermöglichen geführte, regelbasierte Erfassung von (historischen) Texten.
- EpiDoc-TEI-XML nicht auswendig lernen! Das dahinterliegende Schema ist leitend und die Guidelines bieten Beispiele!
Processing Instructions
Schemavalidierung
<? … ?>
<?xml version="1.0" encoding="UTF-8"?>
<?xml-model href="http://www.stoa.org/epidoc/schema/latest/tei-epidoc.rng" schematypens="http://relaxng.org/ns/structure/1.0"?>
<?xml-model href="http://www.stoa.org/epidoc/schema/latest/tei-epidoc.rng" schematypens="http://purl.oclc.org/dsdl/schematron"?>
/schema/latest– validiert gegen das aktuellste Schema/schema/9.0– validiert gegen das versionierte Schema (Release)
Struktur
Metadaten – Bilddaten – Textdaten
<TEI xmlns="http://www.tei-c.org/ns/1.0" xml:space="preserve" xml:lang="en">
<teiHeader>
<!-- Metadaten -->
</teiHeader>
<facsimile>
<!-- Informationen zu Bilddaten-->
</facsimile>
<text>
<!-- Textdaten: Edition, Kommentar, Übersetzung, etc. -->
</text>
</TEI>
Exkurs
Metadaten, Normdaten und Linked Open Data
Metadaten
Why store data about an object, when you have the object itself? Because without data about the objects contained in a space, any sufficiently complex space is indistinguishable from chaos.
Pomerantz 2017
Kleine Merksätze zur Metadaten-Vergabe:
- Ein Metadaten-Schema und ein mindesten projektweites Vergabe-Konzept verwenden; Nutzung[↗] von Normdaten und Authority Files.
- Nicht nur Besonderheiten angeben, sondern alle Zugehörigkeiten explizit machen.
- Keine Datei- oder Sammlungsspezifischen impliziten Annahmen in den Metadaten anwenden (e.g. “Jede Inschrift ohne Trägerangabe ist ein Grabkreuz.”).
Normdaten
Was sind Normdateien?
- Normierte und kuratierte Sammlungen von Informationseinheiten im Kontext eines spezifischen Fachgebietes, e.g. über Personen oder Geographika, in mensch- (👩) und maschinen-lesbarer (🤖) Form (Stichwort content negotiation).
- Die einzelnen Informationseinheiten (“Entitäten”) disambiguieren mittels eindeutiger Bezeichner, e.g. Beispiel GND-Referenzummer:
Normdateien und kontrollierte Vokabulare (Auswahl)
- Geographika
-
Thesaurus of Geographic Names [TGN] kennt Frankfurt am Main als
http://vocab.getty.edu/tgn/7005293; GeoNames alshttp://www.geonames.org/3220968 - Historische Geographika– Pleiades, Pelagios Commons
- Spezifischere Geographika bspw. Judaistik/Hebraistik – Kima Historical Gazeteer
-
Thesaurus of Geographic Names [TGN] kennt Frankfurt am Main als
- Personen
- German National Library Identificators [GND] – Beispiel der Einbindung in das eigene Angebot über DNB Entity Facts und Culture Graph: Epidat, Deutsche Digitale Bibliothel, [🤖]
- Virtual International Authority File
Normdateien und kontrollierte Vokabulare (Auswahl)
- Physische Form | Symbole | Materialien
- Arts and Architecture Thesaurus [AAT] kennt Grabstein als
http://vocab.getty.edu/aat/300266769 - Iconclass –
a multilingual classification system for cultural content
– kennt Lilien alshttp://www.iconclass.org/rkd/25G41%28LILY%29/ - EAGLE [The Europeana network of Ancient Greek and Latin Epigraphy] kennt Eisen als
https://www.eagle-network.eu/voc/material/lod/111
- Arts and Architecture Thesaurus [AAT] kennt Grabstein als
Und was macht man dann damit …? Linked Open Data!
-
LOD auf Basis
von Normdaten ermöglicht automatische Anreicherung, semantische
Verknüpfung und komplexe Analyse von Forschungsdatensets:
- Dritte können meine digitalen Ressourcen finden und nachnutzen.
- Ich gewähre freien, strukturierten und maschinenlesbaren Zugriff (ggf. zu eigenen Analysezwecken).
- Ich biete eine standardisierte Bereitstellung der Informationen nach W3C- und ISO-Standards.
- Ich stelle meine Daten bewusst in einen größeren Kontext und löse Datensilos auf.
LOD am Beispiel von GeoNames-Normdaten und Nomisma
Ansatz: Man sucht Information zu den in der Spät-Antike in Mainz emittierten Münzen, zu den Nominalen und zum Aussteller: Nomisma-SPARQL-Endpoint.
PREFIX nmo: <http://nomisma.org/ontology#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
SELECT ?mint ?label ?denomlabel ?authlabel ?matches
WHERE {
?mint skos:closeMatch <http://www.geonames.org/2874225> .
?type nmo:hasMint ?mint .
?type skos:prefLabel ?label FILTER(langMatches(lang(?label), "en")) .
?type nmo:hasDenomination ?denomination .
?denomination skos:prefLabel ?denomlabel FILTER(langMatches(lang(?denomlabel), "en")) .
?type nmo:hasAuthority ?authority .
?authority skos:prefLabel ?authlabel FILTER(langMatches(lang(?authlabel), "en")) .
?authority skos:exactMatch ?matches FILTER regex(STR(?matches), 'viaf','i') .
}
LIMIT 100
Metadaten innerhalb von TEI und EpiDoc
<teiHeader> – Pflichtelemente
<teiHeader>
<fileDesc> <!-- mögl. vollständige Beschreibung der Datei -->
<titleStmt/> <!-- Titel der Datei -->
<publicationStmt/> <!-- Herausgeber und Bereitsteller der Datei -->
<sourceDesc/> <!-- Beschreibung der (historischen) Quelle -->
</fileDesc>
</teiHeader>
Die Section<sourceDesc>bietet zahlreiche struktierende Elemente zur Beschreibung der Quelle.
<msIdentifier><physDesc><history>
Hinweis
<msDesc> gilt nicht nur für Handschriften, sondern für jedes other
text-bearing object
Weitere Metadaten-Elemente
<teiHeader> – Optionale Elemente
- Weitere Auszeichnungsoptionen:
<encodingDesc><profileDesc>
<particDesc><langUsage>
Weitere Metadaten-Elemente
EpiDoc ermöglicht strukturierte Eingaben zur Beschreibung des Epitaphs, u.a.
<physDesc><objectDesc><objectType><material><layoutDesc><layout><handDesc><handNote><decoDesc><decoNote>
Gleichermassen können Angaben zu Ort und Zeit, Provinenz, Fundorte etc. gemacht werden:
<history><origDate><origPlace><provenance>(auch kopiale Überlieferung)
Quelle: http://www.stoa.org/epidoc/gl/latest/app-allsupp.html
Bilddaten
Bilddateien und andere digitale Faksimiles werden – so möglich mit @url – in der <facsimile>-Sektion aufgeführt.
Quelle:
http://inschriften.net/fileadmin/user_upload/sonstiges/TMP/inschrift_graz_2018_bornschlegel.png
Textdaten – Edition I
Textauszeichnung
- Philologie und historische Wissenschaften nutzen zur Kennzeichnung textueller Phänomene ausgeklügelte und bewährte Klammersysteme. In der Regel werden durch runde, eckige, geschweifte Klammern, sowie durch hoch- und tiefgestellte Zeichen (Punkte, Striche) über, unter oder neben den Buchstaben bzw. Wörtern und Sätzen auf Herausforderungen und Besonderheiten der Textüberlieferung hingewiesen.
- EpiDoc hat diese Notation der Fachwissenschaftler in TEI übertragen. Hinweis: Die Textauszeichnung mit EpiDoc TEI XML ermöglicht die Gewissheit (@cert | @confidence) und die Begründung (@reason) einer textkritischen Entscheidung festzuhalten (siehe auch hier)!
Textdaten – Edition II
Textauszeichnung
- Alle zusammengehörigen Textteile des Inschriftenträgers werden von einem
<div type="edition">geklammert. - Die Transkriptionen der einzelnen Textteile stehen jeweils in spezifischen
<div type="textpart" subtype="pediment" n="A"> <ab> … </ab></div>. Die Angabe vontype="textpart"ist obligatorisch, die Angabe der Attributesubtypeundnist optional.<ab> … </ab>klammern Textblöcke als semantisch-neutrale Alternative zu<p> … </p>. - Die epigraphische Notation wird in XML-Notation nachgebaut. Bsp.:
[Anno]wird zu<supplied reason="lost">Anno</supplied>(siehe auch Leiden Cheatsheet). - Kommentarteil(e), Apparat(e) und Bibliographischer Teil stehen jeweils in eigenen
<div>.
Textdaten – Edition III
Beispiel
<TEI> <!-- Header, Facsimile -->
<text>
<body>
<div type="edition">
<div type="textpart" subtype="pediment" n="I">
<ab>
<lb n="1"/> Lorem ipsum <lb n="2"/> dolor sit
</ab>
</div>
<div type="textpart" subtype="section" n="II">
<ab>
<lb n="1"/> Lorem ipsum <lb n="2"/> dolor sit
</ab>
</div>
<div type="textpart" subtype="base" n="III">
<ab>
<lb n="1"/> Lorem ipsum <lb n="2"/> dolor sit
</ab>
</div>
</div>
<div type="translation">
<p> Translation </p>
</div>
<!-- Commentary, Bibliography -->
</body>
</text>
</TEI>
Textdaten – Edition IV
Beispiel
<TEI> <!-- Header, Facsimile -->
<text>
<body>
<div type="edition">
<!-- Transkription -->
</div>
<div type="translation">
<p> Translation </p>
</div>
<div type="commentary" subtype="description">
<p> Beschreibungstext </p>
</div>
<div type="commentary" subtype="commentary">
<p> Kommentartext </p>
</div>
<div type="apparatus">
<p> Kritischer Apparat </p>
</div>
<div type="bibliography">
<listBibl>
<bibl> Bibliographische Angabe </bibl>
<bibl> Bibliographische Angabe </bibl>
</listBibl>
</div>
</body>
</text>
</TEI>
Textkonstitution I
Graphischer Befund
Unclear:
<unclear>lor</unclear>em
Supraline:
<hi rend="supraline">lorem</hi>
Ligature:
<hi rend="ligature">ab</hi>cd<hi rend="ligature">ef</hi>
Erasure:
<del rend="erasure">ab</del>
Erased and lost:
<del rend="erasure">
<gap reason="lost" quantity="5" unit="character"/>
</del>
Overstrike:
<add place="overstrike">abc</add>
Added above:
<add place="above">γδ</add>
Added below:
<add place="below">γδ</add>
Textkonstitution II
Editorische Hinzufügungen
Supplied (lost):
<supplied reason="lost">γδ</supplied>
Supplied (lost, low certainty):
<supplied reason="lost" cert="low">γδ</supplied>
Supplied (omitted):
<supplied reason="omitted">γδ</supplied>
Supplied (subaudible):
<supplied reason="subaudible">lorem</supplied>
Supplied (parallel):
<supplied reason="undefined" evidence="parallel">lorem</supplied>
Supplied (previous editor):
<supplied reason="undefined" evidence="previouseditor">lorem</supplied>
Textkonstitution IIIa
Lacunae I
Gap or lacuna (lost, character):
<gap reason="lost" quantity="15" unit="character"/>
Gap or lacuna (lost, unknown, character):
<gap reason="lost" extent="unknown" unit="character"/>
Gap (lost, at least–at most, character):
<gap reason="lost" atLeast="5" atMost="7" unit="character"/>
Gap (lost, low precision, character):
<gap reason="lost" quantity="26" unit="character" precision="low"/>
Gap (lost, line):
<gap reason="lost" quantity="1" unit="line"/>
Gap (lost, unknown, line):
<gap reason="lost" extent="unknown" unit="line"/>
Textkonstitution IIIb
Lacunae II
Gap (possibly lost, line):
<gap reason="lost" quantity="1" unit="line">
<certainty match=".." locus="name"/>
</gap>
Gap (possibly lost, unknown, line):
<gap reason="lost" extent="unknown" unit="line">
<certainty match=".." locus="name"/>
</gap>
Gap (omitted, unknown, character):
<gap reason="omitted" extent="unknown" unit="character"/>
Gap (omitted, unknown, line):
<gap reason="omitted" extent="unknown" unit="line"/>
Gap (illegible, character):
<gap reason="illegible" unit="character" quantity="5"/>
Textkonstitution IV
Editorische Eingriffe
Words omitted by editor for brevity:
<gap reason="ellipsis"/>
Superfluous letters:
<surplus>αβγ</surplus>
Clear but incomprehensible:
<orig>αββα</orig>
Correction by editor:
<choice>
<corr>αβ</corr>
<sic>βα</sic>
</choice>
Regularized by editor:
<choice>
<reg>ἐκ</reg>
<orig>ἐγ</orig>
</choice>
Textkonstitution V
Auflösung von Kürzungen
Expansion of abbreviation:
<expan>
<abbr>α</abbr>
<ex>βγ</ex>
</expan>
Tentative expansion of abbreviation:
<expan>
<abbr>α</abbr>
<ex cert="low">βγ</ex>
</expan>
Incomplete expansion:
<expan>α<ex>βγ</ex></expan>
Abbreviation (expansion unknown):
<abbr>αβ</abbr>
Expansion of symbol:
<expan>
<ex>αβ</ex>
</expan>
Textkonstitution VI
Leerstellen, Zahlen, Zahlzeichen, Symbole
Note:
<note>!</note>, <note>sic</note>, <note>e.g.</note>
Space left on stone:
<space quantity="1" unit="character"/>
Space on stone, extent unknown:
<space extent="unknown" unit="character"/>
Numeral (Roman):
<num value="12">ⅩⅡ</num>
Numeral (Greek):
<num value="1">α</num>
Numeral (Greek):
<num value="1000">α</num>
Symbol:
<g type="bear"/>
Textkonstitution VII
Interpunktion, Segmente, Wörter, Wortzeichen
Punctuation (“offene” Semantik):
<g type="punctuation" subtype="word_separator"/>
Punctuation (“geschlossene” Semantik):
<pc type="separator" force="strong" unit="word"/>
Segment & Sentence:
<seg resp="#editor">equiti iosepho me fecit</seg>
<s type="date_line">Anno domini m cccc lxii</s>
Word:
<w lemma="eques">equiti</w>
<w lemmaRef="https://en.wiktionary.org/wiki/eques#Latin">equiti</w>
Character:
<c rend="versalie">e</c>quiti
<c rendition="#versalie">e</c>quiti
Places & Persons:
<rs type="person" ref="#person_0001">Iosepho</rs>
<placeName type="settlement" key="160255975">Graz</placeName>
<persName role="ruler" key="Friedrich, HRR, III., ">Fridericus III.</persName>
Textkonstitution VIII
Allgemeine Attribute
- @xml:id, @n, @xml:lang (Ankerpunkte, Sprachen)
- @key, @ref (Referenzierung)
- @type, @subtype (Typisierung)
- @rend, @style, @rendition (Graphischer Befund)
- @cert, @resp (Verantwortlichkeit)
Leidener Klammersystem
Textauszeichnung
- Basis für traditionelle und digitale Epigraphiker ist das sogenannte Leidener Klammersystem
- EpiDoc Leiden Cheatsheet und korrespondierende
Beispieldatei - EpiDoc Guidelines: Appendix: Aligning EpiDoc with Panciera 1991
- Hilfreich: List Of All Transcription Guidelines
Exkurs
Datenkonversion
Datenkonversion I
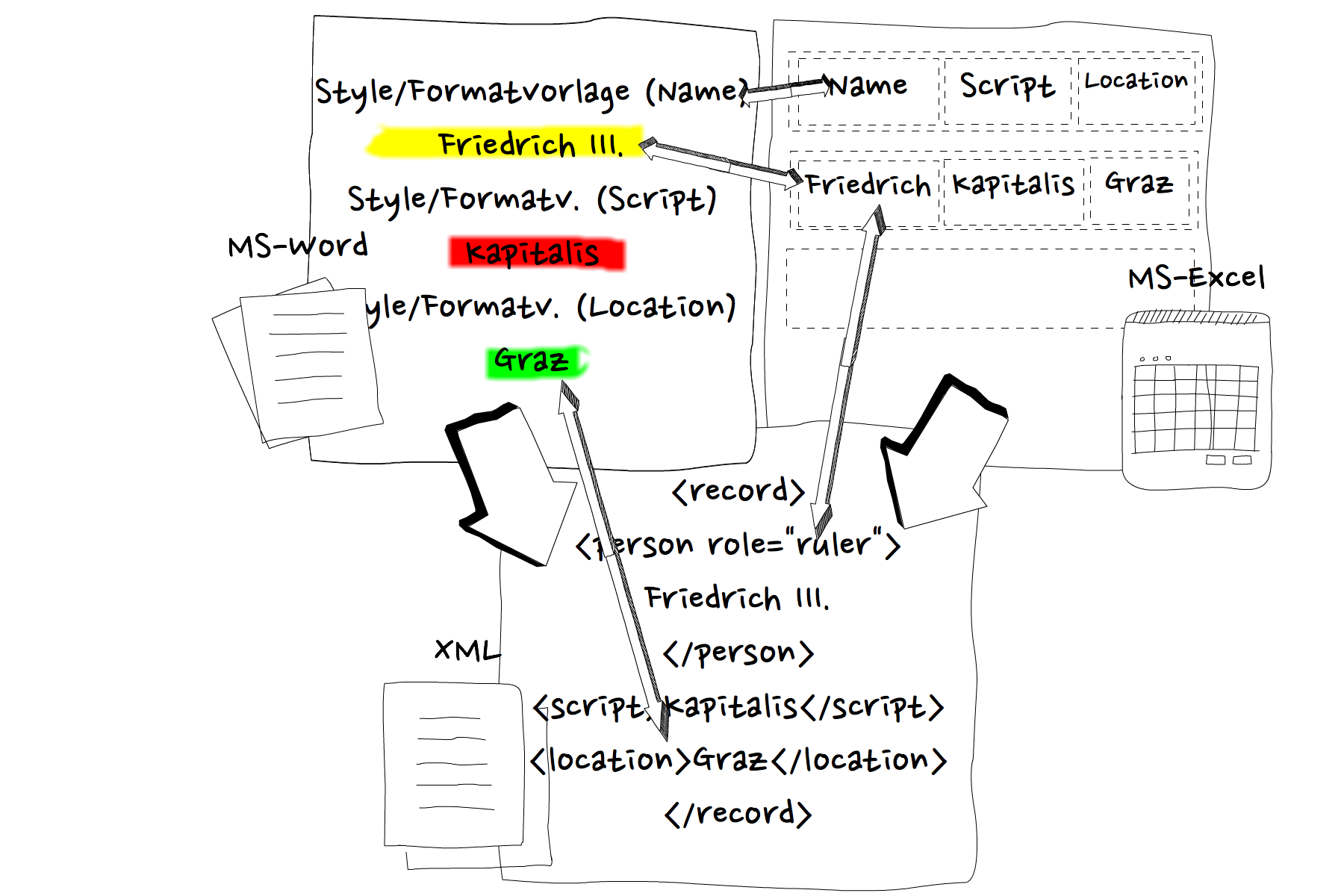
Textverarbeitungs-Dateien, Tabellenkalkulations-Dateien und XML-Dateien können – zumindest in Teilen – in den meisten Fällen mehr oder weniger unproblematisch ineinander überführt werden.
Wichtig ist hierbei nur, dass in den jeweiligen Dateien eindeutig festgelegt ist, welche Funktion und/oder Zugehörigkeit den einzelnen Textbereichen zugeordnet wird. D.h. Namen müssen in Textverarbeitungs-Dateien bspw. mit einer Formatvorlage für “Name” gekennzeichent sein; eine entsprechende Tabellenkalkulations-Datei müsste über eine Spalte “Name” verfügen usw.
Datenkonversion II
Da alle modernen Textverarbeitungs- und Tabellenkalkulations-Programme (MS-Word, MS-Excel, Libre Office) XML-basiert arbeiten, lassen sich die erzeugten Daten mit speziellen Programmen oder Programmier-Libraries ineinander umwandeln.
Zur Konvertierung von XML in MS-Word siehe TEI2RTF von Thomas Kollatz und den OxGarage Web Service. Zur Konvertierung von Tabellenkalkulations-Dateien in XML siehe bspw. Python und die Library Pandas.
Das folgende Schaubild visualisiert die Bezüge der einzelne Bereiche der verschiedenen Dateiformate untereinander.
Datenkonversion III
Diese inhärente Konvertierungsmöglichkeit lässt damit in Bezug auf die Grunddaten-Erhebung einen angenehmen Workflow mit bekannter Software wie MS-Word und MS-Excel zu.
So kann – sofern einheitlich und konsistent mit Formatvorlagen bzw. Spaltenbenennungen gearbeitet wird – eine Grundaufnahme der Quellen in der gewohnten Software geleistet werden. Sobald die Grundaufnahme abgeschlossen ist, werden diese Dateien in das von nun an als Single Source dienende TEI-XML-Format überführt.
Alle weiteren Arbeiten sowie Analyse und Publikation erfolgen daraufhin innerhalb bzw. auf Basis der aus Textverarbeitungs- bzw. Tabellenkalkulations-Dateien konvertierten Daten.
03
Literatur
Allgemeine Literatur zum digitalen Arbeiten und zum Schwerpunkt Linked Open Data
Digitales Arbeiten
- Jannidis F. (2017) Zahlen und Zeichen. In: Jannidis F., Kohle H., Rehbein M. (eds) Digital Humanities. J.B. Metzler, Stuttgart.
- Jannidis F. (2017) Grundlagen der Datenmodellierung. In: Jannidis F., Kohle H., Rehbein M. (eds) Digital Humanities. J.B. Metzler, Stuttgart.
- Vogeler G., Sahle P. (2017) XML. In: Jannidis F., Kohle H., Rehbein M. (eds) Digital Humanities. J.B. Metzler, Stuttgart.
- Sahle P. (2017) Digitale Edition. In: Jannidis F., Kohle H., Rehbein M. (eds) Digital Humanities. J.B. Metzler, Stuttgart.
Linked Open Data
- Pascal Hitzler et. al. (2008) Semantic Web. Grundlagen.Springer, Berlin.
- Leif Isaksen (2011) Archaeology and the Semantic Web. University of Southampton, School of Electronics and Computer Science. Southhampton.
- Max Grüntgens, Torsten Schrade (2016) Data repositories in the Humanities and the Semantic Web: modelling, linking, visualising. In: 1st Workshop on Humanities in the Semantic Web (WHiSe 2016). Anissaras.
Literatur
Digital Humanities Tutorials & Geo-Tools
Literatur zur digitalen Epigraphik
EpiDoc
- EpiDoc homepage on SourceForge
- Markup List: email list for discussions, questions, and help with EpiDoc issues
- EpiDoc Guidelines
- EpiDoc Stylesheets
Digitale Epigraphik
- H. Cayless; C.M. Roueché; Tom Elliott; Gabriel Bodard (2009): “Epigraphy in 2017.” Digital Humanities Quarterly 3.1. http://digitalhumanities.org/dhq/vol/3/1/000030/000030.html
- Max Grüntgens, Thomas Kollatz (2018) Korpusbasiertes Arbeiten und epigraphische Datenbanken: Möglichkeiten und Herausforderungen am Beispiel von EPIDAT und DIO. In: Gessinger, Redder, Schmitz: OBST, H. 92/2018.
- Felix Lange, Martin Unold (2015) Semantisch angereicherte 3D-Messdaten von Kirchenräumen als Quellen für die geschichtswissenschaftliche Forschung. In: Baum, Stäcker: Möglichkeiten und Grenzen der Digital Humanities. Sonderband 1 der ZfDH. DOI: 10.17175/sb001_015
- Julia Flanders; Charlotte Roueché Erste Einführung in die Textauszeichnung für Epigraphiker
Präsentationen
- Thomas Kollatz: Digital Approaches to Cemeteries: Preservation and Education. workshop All that remains: education and conservation of Jewish Funerary Culture. Utrecht 2018
- Max Grüntgens; Thomas Kollatz: Digital Humanites and Jewish Epigraphy EAJS-Winterschool. Utrecht 2019
- Max Grüntgens; Dominik Kasper; Thomas Kollatz: EpiDoc TEI XML Grundlagen und Einführung, Praxis und Vertiefung. Mainz 2018
- Thomas Kollatz: Sharing Data. The case of Jewish funerary inscriptions databases. Jerusalem 2017
- Thomas Kollatz: epidat: Database of Jewish Epigraphy. Leeds 2017
Download
- https://github.com/digicademy/2018-EpiDoc-WS-1
- Sofern nicht anders angegeben stehen alle Texte, Illustrationen und Bilder frei zur Weiterverwendung und Modifikation zur Verfügung unter der CC-BY 4.0 Lizenz, Max Grüntgens, Thomas Kollatz.
Handouts und weitere Informationen
Handouts
Weitere (Summer/Winter) Schools
- to be announced
Lizenzinformationen
- The “IM Fell English SC” font by Igino Marini (Principal design) is licensed under the Open Font License (http://scripts.sil.org/cms/scripts/page.php?site_id=nrsi&id=OFL_web) and available via Google Web Fonts (https://fonts.google.com/specimen/IM+Fell+English+SC?selection.family=IM+Fell+English+SC).
Software
- Impress.js (Presentation)
- hightlight.js (Syntax Highlighting)
- tei-documentation-links.js (Links to TEI-P5-XML documentation)